大家好,我是蓝戒,本文我们来聊聊”llmfit“
别再盲下大模型了:用 llmfit 一秒看懂你的电脑到底能跑谁
你有没有过这种经历:
兴冲冲看到一个“超强开源大模型”,心里一热,手一抖,开始下载。
等了半天,模型终于躺进了硬盘。
结果一运行,电脑当场表演“原地去世”。
要么显存不够,要么内存爆掉,要么速度慢得像在用算盘做推理。
这时候你就会发现,本地跑大模型这件事,最怕的不是模型不够强,而是你根本不知道它能不能在你电脑上活下来。
而 llmfit 的出现,恰好就是为了解决这个非常现实、非常朴素、也非常让人抓狂的问题:
在你下载模型之前,先告诉你——你的电脑到底适合跑什么。
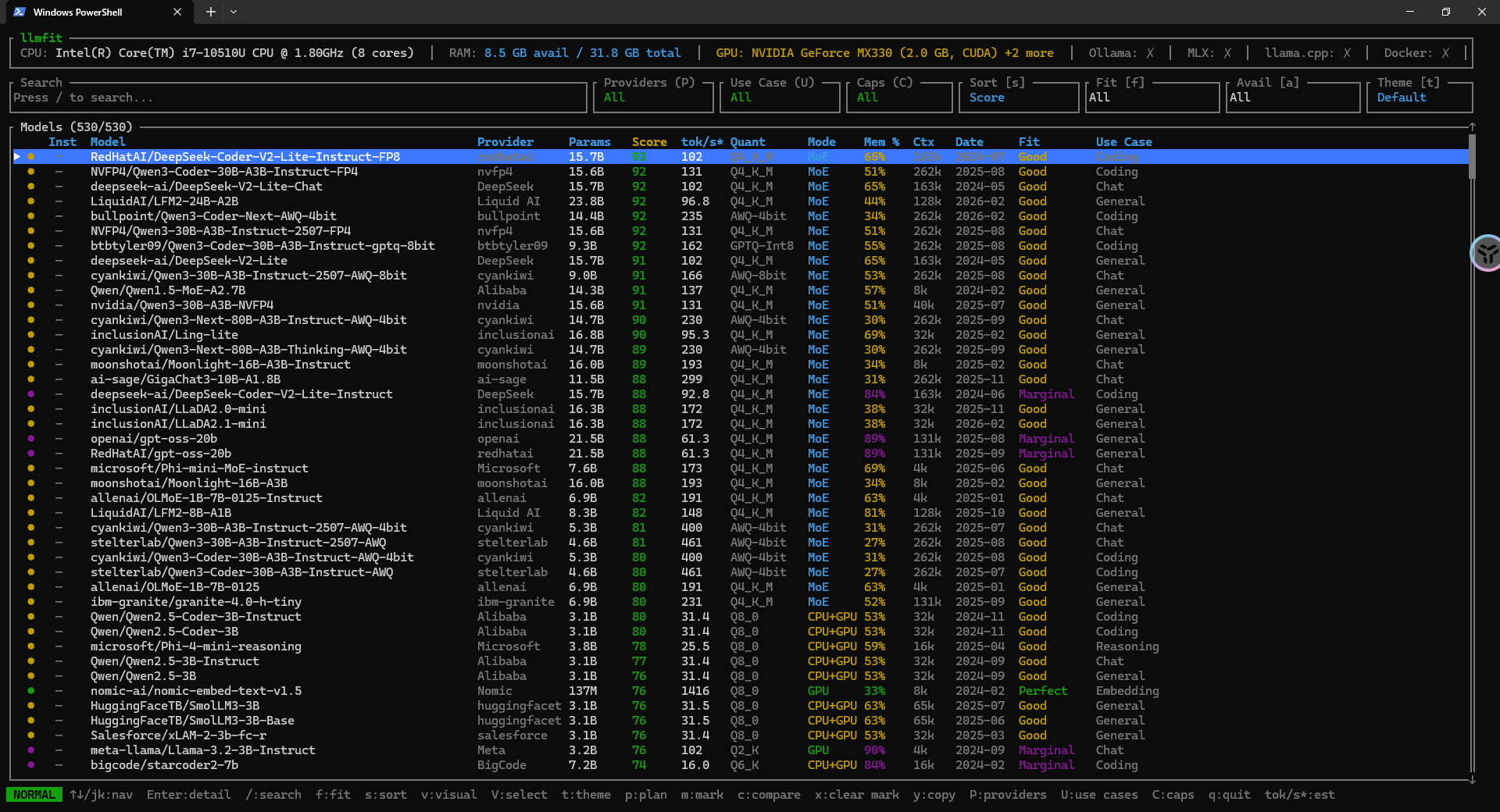
一句话认识 llmfit
简单说,llmfit 是一个面向本地大模型场景的工具。
它会自动检测你的机器硬件配置,比如 CPU、内存、GPU、显存等,然后把这些信息和模型数据库做匹配,告诉你哪些模型更适合你的设备运行。
它不只是简单回答“能跑”还是“不能跑”。
它还会进一步从质量、速度、适配度、上下文能力等维度给出综合评分。
换句话说,llmfit 更像一个“大模型硬件顾问”。
它不负责替你写提示词,也不负责帮你训练模型,但它特别擅长做一件事:
帮你在本地部署之前,减少踩坑、节省时间、避免“下了个寂寞”。
为什么 llmfit 这么有用
很多人刚接触本地 LLM,会以为最难的是提示词、部署命令,或者环境配置。
其实真正高频劝退新手的,往往是“选错模型”。
模型参数量看着差不多,实际资源占用却可能差很多。
同样都是 7B,有的量化后很友好,有的依然非常吃资源。
有些模型上下文长,但速度慢得让人怀疑人生。
还有一些模型看着参数巨大,但因为架构设计的原因,实际运行需求又没有想象中那么夸张。
普通用户如果全靠经验判断,试错成本会非常高。
而 llmfit 的价值就在这里:
它把“凭感觉选模型”,变成“基于机器条件做判断”。
这件事看起来朴素,实际上非常关键。
因为本地部署不是云端调用,不是“API 一接,全都能跑”,而是你必须正视硬件这位现实主义导师。
更直白一点说,llmfit 让本地大模型从“玄学”变成了“算学”。
llmfit 到底强在哪
llmfit 最核心的能力,首先是自动检测硬件。
它会识别 CPU、系统内存、GPU 类型以及显存情况,让你先清楚自己机器的底子到底如何。
第二,它能把你的硬件条件和大量模型做匹配。
这意味着你不用自己在“这个模型看起来不错”和“我机器到底行不行”之间来回横跳,工具已经替你把信息做了结构化处理。
第三,它有一套比较实用的评分逻辑。
它不只是告诉你“能不能跑”,还会从质量、速度、适配度、上下文等多个维度综合判断。
这就像你去相亲,不只是问“人来了没”,还得看“聊不聊得来、消费观合不合、以后能不能过日子”。
大模型也是一样。
能启动,不代表适合长期用。
第四,它会尽量给出更合理的量化建议和速度预估。
这点特别重要。
因为很多人本地跑模型失败,不是因为模型绝对跑不了,而是因为选错了量化版本,或者高估了机器性能。
llmfit 做的事情,就是尽量在下载和部署之前,把这些坑提前告诉你。
它适合哪些人
如果你是刚开始折腾本地 AI 的新手,llmfit 很适合你。
你不需要先成为“显存民间统计学家”,也不需要把各种模型参数背得像元素周期表。
先让工具给你一个合理范围,再决定下载什么,效率会高得多。
如果你是开发者,它的价值会更直接。
很多开发流程里,模型选择其实是前置条件。
你得先知道这台开发机、测试机或者边缘设备适合跑什么,再去决定推理方案、应用架构,甚至产品体验。
如果你是学生、研究者、内容创作者,或者只是单纯想在本地试试 AI,它也同样友好。
它能帮你节省下载、部署和反复报错的时间,把更多精力留给真正有意思的事情:
使用模型,而不是和配置斗智斗勇。
它和普通“模型推荐”有什么不一样
网上其实不缺“大模型推荐榜单”。
缺的是“适合你电脑的推荐榜单”。
这是两个完全不同的概念。
很多榜单只会告诉你哪个模型强,哪个模型火,哪个模型参数大。
但它们不会告诉你:
你的电脑是不是能稳稳当当跑起来。
而 llmfit 更务实。
它不是先谈理想,而是先看现实。
先看你的显存够不够,内存扛不扛得住,速度能不能接受,再决定推荐什么模型。
这种思路最大的价值就在于:
它不浪费你的时间,也不浪费你的硬盘,更不浪费你的耐心。
本地跑 AI,最怕的到底是什么
很多人以为本地跑 AI 最怕的是“设备不够强”。
其实不完全是。
真正最折磨人的,往往是信息不对称。
你不知道哪个模型适合自己,不知道该下哪个版本,不知道该选什么量化,不知道为什么别人能跑你却不行。
于是整件事就变成了:
下载靠运气,部署靠玄学,报错靠搜索,成功靠缘分。
而 llmfit 本质上是在补这层信息差。
它让你在下载前先知道方向,在部署前先降低风险,在折腾前先拥有一点确定性。
对于本地 AI 这件事来说,这种确定性非常宝贵。
llmfit 为什么符合当下趋势
这两年,越来越多人开始认真考虑本地运行大模型。
原因很现实。
第一是隐私。
本地运行意味着你的内容不用上传到远端,很多敏感资料、代码、文档会更放心。
第二是成本。
云端模型调用虽然方便,但如果使用频繁,成本并不低。
而本地模型通常是一次下载,长期使用。
第三是灵活性。
离线可用、内网可用、可自由调试、可按自己的需求折腾,这些都是本地 AI 很有吸引力的地方。
但本地化真正的门槛,从来都不是“有没有模型”,而是“如何把模型和设备合理配对”。
在这个环节里,llmfit 的价值就出来了。
它很像导航软件。
它不替你开车,但它能防止你把车直接开进沟里。
使用 llmfit 时,也别把它当魔法棒
当然,llmfit 很有用,但它不是魔法。
它提供的是高价值参考,而不是绝对真理。
首先,速度预估本质上仍然是预估。
真实表现还会受到量化版本、上下文长度、推理后端、并发情况等因素影响。
所以你可以把它理解为“靠谱预判”,但别把它当成“官方保底承诺”。
其次,硬件检测虽然方便,但在一些特殊环境下,也可能出现识别偏差。
比如驱动状态不正常,或者运行环境比较特殊时,识别结果就可能和实际情况有出入。
所以第一次使用时,最好还是先确认一下它识别出来的 CPU、GPU、显存是否合理。
再者,它解决的是“选哪个模型更合适”,而不是“这个模型在你的具体业务上一定最好”。
模型是否真正适合你,仍然要结合任务类型、语言需求、上下文长度需求、是否偏重代码、是否偏重推理等实际场景来判断。
为什么我觉得 llmfit 值得推荐
因为它踩中了一个特别关键的点:
它尊重现实。
在 AI 领域,很多工具喜欢先画大饼,告诉你“未来已来”“万物皆可智能化”。
但 llmfit 很接地气。
它先看你电脑几斤几两,再告诉你今晚到底该下载哪个模型。
别浪费时间,别折腾硬盘,别让风扇白转。
这种工具看起来不花哨,却特别有生产力。
它的意义不在于“让所有人都跑上最强模型”,而在于“让更多人用现有设备,跑上最合适的模型”。
这其实比盲目追求参数更务实,也更符合本地 AI 走向普及的路径。
写在最后
本地跑大模型,最怕的不是配置低,而是信息不对称。
你以为自己差一张显卡,结果可能只是差一个靠谱的选型工具。
llmfit 的价值,恰恰就在于把这层信息差补上。
它让你在下载之前就知道方向,在部署之前就降低风险,在折腾之前就先拥有一点确定性。
对于每一个不想再靠“试试运气”来选模型的人来说,llmfit 都值得一试。
毕竟,和大模型谈恋爱之前,先看看八字合不合,总不是坏事。


文章评论