大家好,我是蓝戒,本篇我们来聊聊“bb-browser”
AI 会写代码、会调 API、会读文档,但一到“真正上网”这一步,很多能力就突然掉线了。
原因很简单:互联网从来不是为 Agent 设计的,而是为浏览器设计的。
这也是我最近看到 bb-browser 时,觉得它特别值得聊的原因。它没有沿着传统思路继续卷“更强的爬虫”“更稳的反爬”“更复杂的浏览器自动化”,而是直接换了一个方向:
既然绝大多数网站都没有为机器提供好用的 API,那就别逼网站适配机器了,干脆让机器直接使用人类已经在用的浏览器。
一句话概括它的核心理念就是:
你的浏览器就是 API。
这句话看上去有点狂,甚至有点“不讲武德”,但越往下看,你越会发现这不是一句口号,而是一套非常有现实感、也非常有想象力的工程思路。
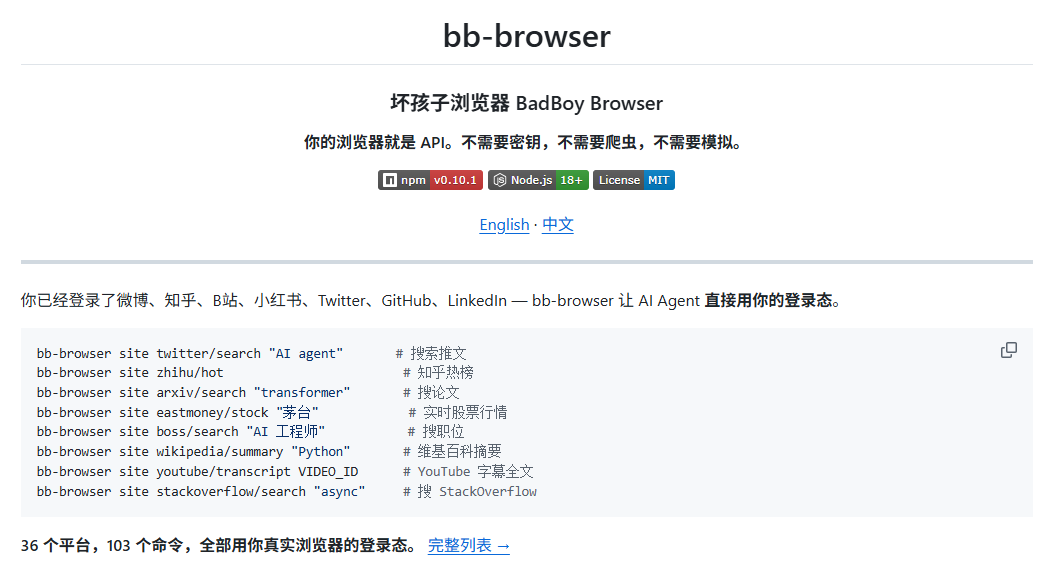
根据项目公开资料,bb-browser 通过 Chrome 扩展、CLI、Daemon 和 MCP Server,把你已经登录好的真实浏览器,变成 AI Agent 可以直接调用的互联网入口。它当前公开列出的能力包括 36 个平台、103 个命令,覆盖搜索、社交媒体、新闻、开发、视频、金融、招聘、知识等多个场景。
为什么这个项目一眼就让人上头?
很多人第一次接触这类工具,最容易忽略的一点是:
真正麻烦的从来不是“打开网页”,而是“以真实用户身份稳定地打开网页”。
写过爬虫的人都懂,最痛苦的根本不是解析 HTML,而是登录态、Cookie、Token、签名、风控、反爬、权限、上下文。
你可能今天刚把脚本跑通,明天接口参数就变了;你可能本地抓到请求了,线上一跑就被拦;你可能好不容易拿到了 Cookie,过几天又失效;你可能以为自己在调接口,实际上还在跟网站的一整套前端运行时博弈。
问题并不是开发者不够努力,而是你一直站在网站外面,试图模仿一个用户。
bb-browser 的思路恰恰相反:既然你本来就在浏览器里,为什么不让 AI 直接进入这个浏览器上下文?
项目文档里写得很直白,它不是要求网站提供额外接口,而是让适配器直接运行在你的浏览器标签页中,可以在页面上下文里执行逻辑、调用带着你 Cookie 的 fetch(),甚至在必要时借用页面自己的模块能力。网站为什么会把请求当成“真实用户行为”?因为它确实就是从真实用户的浏览器里发出去的。
它到底厉害在哪?不是“自动化”,而是“换解法”
这件事听起来很简单,但它改变的,其实是 Agent 访问互联网的基本假设。
过去的默认思路是:Agent 想联网,先找 API;没有 API,就写爬虫;爬虫不稳,就上无头浏览器;无头浏览器被识别,就继续想办法绕。整个过程像是在一堵墙外面不断加长梯子。
而 bb-browser 做的,是直接去开门。
它没有试图把互联网改造成机器友好型世界,而是承认一个事实:人类早就有一套成熟的互联网访问入口,那就是浏览器。登录态、鉴权、前端状态、交互上下文,全都已经存在。与其重新复制一遍,不如直接拿来用。
这就是为什么我会觉得 bb-browser 不是“又一个自动化工具”,而是一种可能会影响 AI Agent 落地方式的基础思路。
它的架构不花哨,但很聪明
从公开信息来看,bb-browser 的整体架构并不花哨,但很有效。
上层既可以通过 CLI 使用,也可以通过 MCP Server 接入 Agent 工作流;中间由 daemon 负责通信;再通过 Chrome 扩展连接真实浏览器,最终借助浏览器调试能力完成操作。项目还提供了 OpenClaw 模式,在特定场景下甚至不需要额外装扩展。
这种设计有一个特别现实的优点:它不是把自己做成“只能演示、很难接入”的玩具,而是尽量让它能进入真实工作流。
你可以把它当成独立命令行工具来用,也可以把它当成 MCP Server 接给 Claude Code、Cursor 这类 Agent 工作环境。换句话说,它不是一个“功能”,而是一层“能力接口”。
真正关键的一步:它不是点网页,而是在“适配网站”
真正让我觉得这个项目有潜力的地方,是它没有停留在“能控制浏览器”这件事上,而是继续往前走了一步:把网站能力抽象成了 Site Adapter。
这点非常关键。
因为如果只是控制浏览器,那它的价值更多还是自动化;但如果它把网站操作进一步抽象成一条条可调用命令,那它就开始接近“互联网能力层”了。
从 README 看,bb-browser 的命令体系已经覆盖了不少主流场景。比如搜索引擎、社交平台、开发社区、视频平台、财经网站、招聘网站、百科知识等,都有对应适配器。命令背后依赖的是社区维护的 bb-sites 仓库,每个命令本质上就是一个 JS 文件。也就是说,bb-browser 想做的不是“帮你点页面”,而是“把网站变成结构化接口”。
这一步一旦成立,意义就很不一样了。
因为一个工具最怕每次都从零开始。今天为了某个平台写一套脚本,明天为了另一个平台再写一套;每次都得重新理解页面、重新抓包、重新处理认证,效率极低,也几乎无法形成复用。
但 Site Adapter 的思路是,一次抽象,长期复用;一个人打通,社区共享;AI 不只是用工具,还能继续扩展工具。
最有想象力的地方:AI 可以给自己“修路”
项目文档里甚至把新增网站的过程讲得非常激进:如果网站不在列表里,可以让 AI Agent 去读 guide、抓网络请求、分析认证方式、写 adapter、测试、提交 PR。README 里把适配器复杂度分成三层,最简单的站点可能一分钟左右就能搞定,复杂一些的三分钟、十分钟级别。
你可以说这个表述很理想化,但这并不影响它传递出的信号:bb-browser 正在降低“让一个网站被 Agent 使用”的边际成本。
这一点,可能比它已经支持了多少平台更重要。
因为平台数量只能说明现在,扩展机制才决定未来。
真实案例 1:它不是从概念出发,而是从真实痛点出发
而且,这个项目最有意思的地方在于,它不是凭空画饼,它背后已经有一些很能说明问题的真实案例。
一个非常典型的案例,来自作者自己的公开分享。
他提到,这个项目最初并不是为了做一个“大而全”的 Agent 上网系统,而是为了解决自己一个很具体的小问题:在社区平台上看评论、整理内容、翻译回复时,整套流程太手工了。看评论、复制、贴给 AI、翻译、组织回复、再粘贴回去,重复又低效。于是他开始想,能不能让 Agent 直接借助自己已经登录的浏览器来处理这件事。结果,一个 Reddit 适配器很快做出来了,后面更多网站也顺着这个思路接了进来。
这个故事特别值得注意,因为它不是“先做技术,再找场景”,而是从一个真实到不能再真实的工作流痛点长出来的。
很多产品的问题在于,概念很大,落地很虚;但 bb-browser 这个出发点非常朴素:我已经登录了网站,我已经在浏览器里了,为什么 AI 不能直接利用这个环境?
真实案例 2:复杂签名问题,换个姿势就解了
另一个更有冲击力的案例,是作者提到的复杂站点搜索接口问题。
公开分享中提到,某社交平台的搜索请求依赖动态生成的签名参数,这类机制对传统爬虫来说非常头疼,因为你需要在站外复刻网站内部逻辑,一旦网站更新,脚本就容易失效。
结果在 bb-browser 的思路下,处理方式不是“在外面猜”,而是直接进入页面自己的模块体系里调用已有函数,让页面自己完成签名,然后再发起请求。
这个案例为什么重要?
因为它揭示了 bb-browser 最核心的价值:不是提高了多少“抓取速度”,而是换掉了问题的求解方式。
传统爬虫是在浏览器外面复制一个浏览器;bb-browser 是直接进入浏览器里面借力。
这两者的稳定性、维护成本和扩展效率,往往差得不是一点半点。
真实案例 3:20 个 Agent 并发做适配器,这味道就不一样了
还有一个广为传播的案例,是多 Agent 并发生成适配器。
根据项目 README 和作者公开分享,曾有 20 个 Agent 并行处理多个网站,分别完成抓包、识别认证方式、编写 adapter、测试验证等工作,最终快速扩充了社区适配器数量。README 中甚至明确写到,把新网站纳入 Agent 可访问互联网的边际成本正在接近零。
如果这件事能持续成立,那它的意义其实已经超出单个项目了。
因为这意味着 Agent 的能力建设,不再只是开发者手工堆工具,而开始出现一种“Agent 为自己造工具,再把工具沉淀进生态”的自增长模式。
说得更直白一点:以前我们总说 AI 会用工具,但 bb-browser 让人看到的,是 AI 正在开始为自己修路。
它最真正的价值:重新定义了“联网成本”
这也是为什么我认为 bb-browser 的价值,不只是“提高效率”,而是“重新定义联网成本”。
过去,给 Agent 接互联网的代价,取决于平台愿不愿意给 API、接口难不难逆、授权复不复杂、风控严不严、文档全不全。这些东西开发者很多时候没有主动权。
但在 bb-browser 这里,成本模型变成了另一种样子:只要你能在浏览器里正常访问网站,只要有人能把它抽象成一个适配器命令,这个网站就有机会被纳入 Agent 的工作流。
这就把“互联网接入权”从平台端,部分拉回到了用户与开发者手里。
放到真实工作流里,它到底能怎么用?
而且,这个思路非常适合当下 AI Agent 的真实使用场景。
1. 跨平台信息研究
过去你想调研一个主题,要自己分别去搜索引擎、论文站、社区论坛、代码仓库、新闻网站、问答平台搜一圈,再手动整理。
现在如果 Agent 能直接调用这些站点能力,把不同来源结果统一成结构化数据,那它做的就不再只是“搜索”,而是“跨平台研究助理”。项目文档中也给出了类似示例:围绕同一主题跨多个平台获取结果,统一输出 JSON。
2. 登录态内容访问
很多真正有价值的内容,并不在公开页面上,而在你的关注流、收藏夹、个性化推荐、订阅列表、观察列表、已登录社区视图里。
传统工具往往在这些地方就失效了,因为缺失真实会话。而 bb-browser 的优势恰恰在于,它不是从外部硬闯,而是借助你已有的登录环境进入这些场景。
3. 日常自动化与信息搬运
每天汇总行业资讯、筛选 GitHub 项目动态、整理招聘信息、跟踪财经数据、提炼社区讨论、辅助内容选题,这些工作本质上都不复杂,但极其消耗时间。
一个真正好用的 Agent,不一定要替你做所有决策,但至少应该能先把信息搬运、归类、结构化。bb-browser 在这一步上,很可能比很多“高概念 Agent”更接地气。
当然,它也不是没有边界
聊到这里,也必须说清楚:bb-browser 并不是没有边界。
首先,它非常依赖真实浏览器和真实登录态,所以它天然更适合个人电脑、开发环境、可信工作站,而不一定适合完全无状态、标准化、纯后端的云端批处理场景。
其次,因为它连接的是你的真实账号环境,所以权限、会话、隔离和安全边界一定要认真处理。作者在公开分享里也提到过一个很实用的建议:可以专门准备一个浏览器实例,登录常用网站,把它作为 bb-browser 的工作浏览器,而不是直接拿主浏览器裸奔。这个建议听起来朴素,但其实非常重要。
再者,它也不意味着官方 API、传统爬虫、常规浏览器自动化就没价值了。标准化、正式集成、长期稳定的业务链路里,官方 API 依旧是优先选项;页面测试、行为脚本、固定自动化任务,也仍然有成熟工具可用。
bb-browser 解决的,更像是一块长期没人真正补好的空白地带:当网站没有开放合适接口,但人类又确实能正常使用时,Agent 终于有机会以低摩擦方式接入这个网站。
为什么我觉得它值得持续关注?
这正是它最迷人的地方。
它不是一套理想化的“未来互联网标准”,而是一套极其现实的“今天就能工作”的方案。
它没有要求整个世界为 AI 重写一遍接口,而是直接借用了人类已经构建好的那套入口。它也没有执着于最优雅、最正统的工程路径,而是优先考虑最有效、最贴近真实场景的那条路。
所以如果你问我,bb-browser 到底值不值得关注,我的答案是:非常值得。
不是因为它已经完美了,而是因为它抓住了一个很多人都忽视、但又极其关键的问题——AI Agent 真正缺的,未必是更强的模型,而是更低成本、更少阻力、更贴近现实的互联网访问能力。
最后
bb-browser 给出的回答是:别再逼互联网适配 Agent 了,让 Agent 去使用浏览器。
而浏览器,本来就是人类世界最通用的互联网 API。
在这个意义上,bb-browser 最厉害的,并不是帮 AI 学会了“自动打开网页”,而是让 AI 第一次更像一个真正活在互联网里的使用者。
开源地址: GitHub:https://github.com/epiral/bb-browser


文章评论