大家好,我是蓝戒,本篇我们来聊聊 “谷歌开源大模型 Gemma 4”
能看图、能写代码、能做 Agent、还能本地跑。Gemma 4 这次,真的有点东西。
这次,谷歌不是来刷存在感的
AI 圈最近的节奏,已经快赶上短视频平台了:
你刚记住一个模型名字,下一秒又冒出来一个“更强、更快、更便宜”的新选手。
但这次不太一样。
因为谷歌正式发布了 Gemma 4,而且这一次它不是单纯来“秀肌肉”的,而是直接瞄准了一个非常现实的方向:
让大模型真正跑进本地设备,跑进开发者工具链,跑进实际工作流。
说得再直白一点:
Gemma 4 主打两个关键词:
- 本地运行
- 多模态能力
如果你最近正好在关注这些问题:
- 有没有值得本地部署的大模型?
- 有没有既强、又能商用、还不至于把显卡烧红的模型?
- 有没有可以拿来写代码、做自动化、跑 Agent、看图识图的本地 AI?
那 Gemma 4,真的值得你认真看一眼。
先说结论:Gemma 4 到底值不值得关注?
我的判断很直接:
值得,而且是非常值得。
原因不是因为它“又是一个新模型”,而是因为它同时踩中了当下本地 AI 最重要的几条主线:
- 模型能力够强
- 支持多模态
- 支持 Agent 工作流
- 许可更宽松
- 可以在本地或边缘设备运行
- 生态接入速度很快
一句话总结就是:
Gemma 4 不是那种“看起来很厉害,真用起来很费劲”的模型。它更像是谷歌认真做出来的一套“能打、能跑、能落地”的开放模型家族。
Gemma 4 是什么?一句人话解释清楚
Gemma 4 是 Google DeepMind 推出的新一代 开放权重模型家族。
这里有个小细节必须说清楚:
很多文章喜欢直接写“谷歌开源了 Gemma 4”。
这句话不算全错,但更严谨的说法其实是:
Gemma 4 是开放权重模型(open-weight model)。
也就是模型权重可获取、可部署、可商用条件更友好,但它不等于那种把所有训练细节、数据、流程全部摊开给你看的“完全开源软件项目”。官方表述也是 open models / open weights。
不过,对大多数开发者来说,这已经很香了。
因为这次更重要的一点是:
Gemma 4 采用的是 Apache 2.0 许可
这意味着什么?
意味着它对开发者很友好:
- 可以免费商用
- 可以修改
- 可以二次开发
- 可以私有部署
- 可以更放心地拿去做项目
你可以理解为:
很多模型强是强,但你真要落地时,总感觉法务会先比你紧张。Gemma 4 这次,至少在许可层面,明显让人安心很多。
Gemma 4 一共有哪几个版本?
这次谷歌一共推出了 4 个主要版本:
- E2B
- E4B
- 26B A4B
- 31B
看到这几个名字,第一次确实容易懵。
别慌,我们直接翻译成人话。
E2B / E4B:轻量选手,适合移动端和边缘设备
E2B 和 E4B 中的 E,指的是 effective parameters(有效参数)。
官方给出的信息大致是:
- E2B:约 2.3B 有效参数
- E4B:约 4.5B 有效参数
这两个版本的主要定位很明确:
低资源设备、本地端侧、轻量部署。
适合谁?
- 想在手机、平板、边缘设备上跑模型的人
- 想做本地 AI 助手的人
- 想先低成本体验 Gemma 4 的人
- 对响应速度比较敏感的人
而且这两个小模型还不只是能处理文本。
官方资料显示,它们还支持:
- 图像输入
- 音频输入
- 多模态理解
这就很有意思了。
以前很多“小模型”的存在感,基本就是“能跑起来”。
Gemma 4 这次的思路明显不是“凑合能用”,而是:
小模型也要认真干活。
26B A4B:很可能是最香的“甜点位”
这个版本特别值得聊。
26B A4B 是一个 MoE(专家混合)模型,总参数大约 25.2B,但推理时激活参数只有 3.8B。
这意味着什么?
你可以把它理解成:
看起来是个 26B 的大家伙,实际跑起来更像是一个更轻巧、更省资源的高手。
这类模型最适合什么场景?
- 想要比小模型更强的推理能力
- 想做代码助手
- 想跑 Agent
- 想做自动化工作流
- 想兼顾效果和速度
说得更直接一点:
如果你不是“收藏党”,而是真想找一个本地能干活的大模型,26B A4B 很可能是 Gemma 4 里最值得优先试的版本。
31B:旗舰选手,主打一个“我全都要”
31B 是这次 Gemma 4 家族里的旗舰稠密模型,参数大约 30.7B,上下文长度支持到 256K。
它适合谁?
- 追求更强推理效果的人
- 追求更好代码能力的人
- 想让本地模型尽量接近高端体验的人
- 机器配置比较顶的人
你可以把 31B 理解成一句话:
“这代 Gemma 里最能打的,基本就是它。”
Gemma 4 到底强在哪?不是参数大,而是效率高
现在很多人看模型,已经不太迷信“参数越大越强”了。
原因很简单:
参数大,不等于体验好;
模型大,也不等于能落地。
Gemma 4 这次最关键的一点,就是它非常强调:
单位参数的智能水平。
官方博客提到,Gemma 4 在 Arena AI 文本榜单上的表现非常亮眼:
- Gemma 4 31B:排名第 3
- Gemma 4 26B A4B:排名第 6
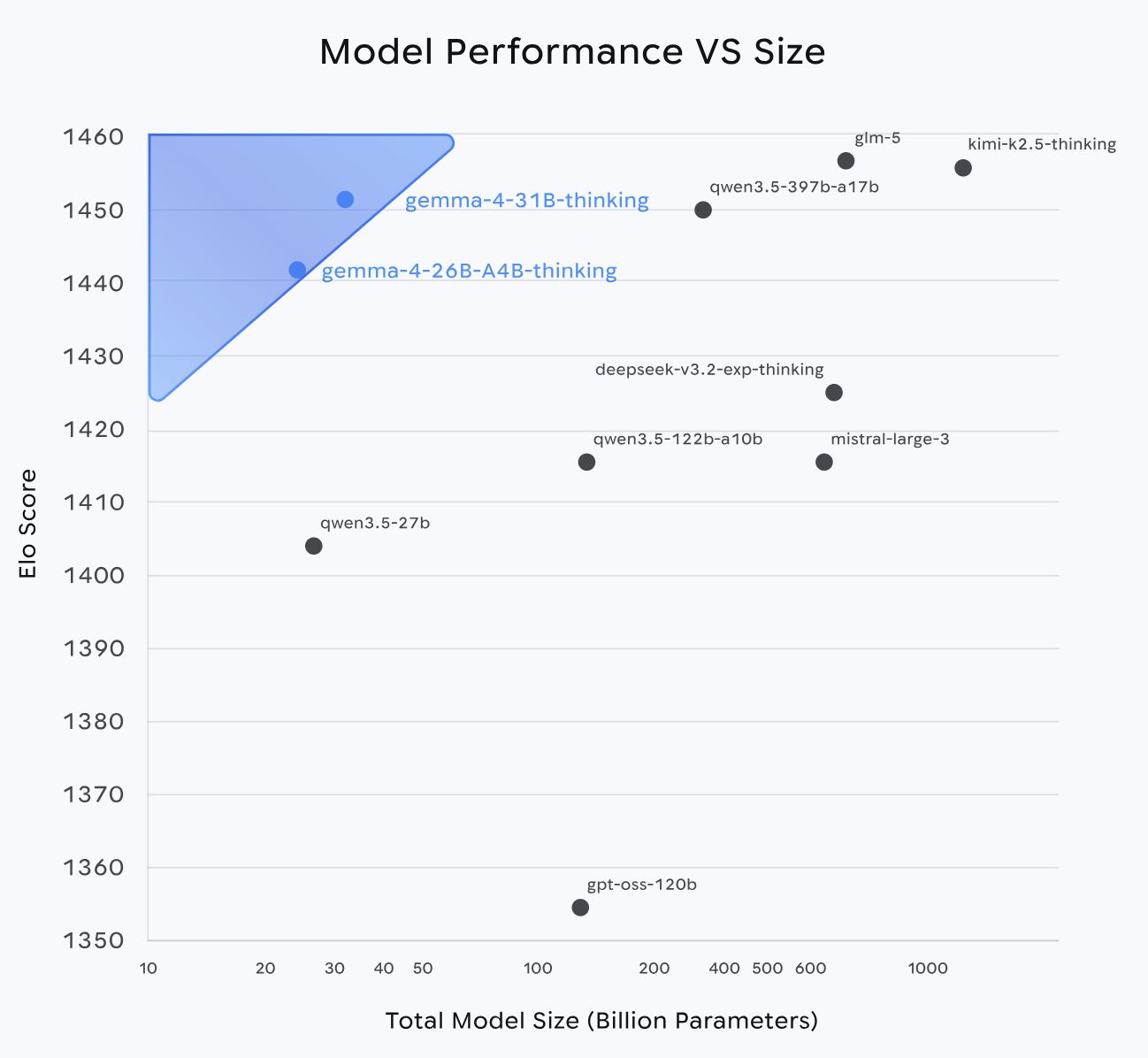
而且谷歌还特别强调,它们在一些公开评测里甚至超过了参数规模更大的模型。
同时,官方 model card 里给出的多项基准测试成绩也说明,这代模型在:
- 数学推理
- 代码生成
- 科学问答
- 多模态理解
这些能力上都表现不俗。
所以,Gemma 4 的强,不是那种“硬堆体积”的强,
而更像是:
脑子转得快,身体还不笨重。
这就很适合本地部署。
因为大家最怕的不是模型不够大,
而是模型大到你根本不想开。
Gemma 4 的核心能力,一次给你说清楚
Gemma 4 之所以热度这么高,不只是因为它跑分不错,更因为它具备了一套比较完整的能力组合。
1. 多模态能力:不只是会聊天
Gemma 4 支持 文本 + 图像 输入,E2B / E4B 还支持 音频。
这意味着它不再只是一个“聊天模型”,而是能处理更复杂的真实输入。
比如:
- 看图说话
- OCR 识别
- 文档理解
- 图表分析
- 屏幕界面理解
- 视频帧序列分析
换句话说:
以后你给它一张界面截图,它不只是说“这是一张图”。
它更可能告诉你:
“这是一个后台管理页面,左边是导航栏,中间是数据面板,你这个按钮位置可能不太合理,顺手我还能帮你生成一版前端代码。”
2. 推理能力:不是乱答,是更会“想”
Gemma 4 官方文档专门提到了 thinking mode。
这意味着它在很多复杂任务中,更强调分步骤推理,而不是一本正经地胡说八道。
当然,我们也别神化。
所谓“thinking”并不是 AI 突然参透宇宙真理了,
而是它更擅长在复杂问题上给出结构化、相对稳一点的思考过程。
对于用户来说,这就很重要:
至少它更像在认真做题,而不是边写边编。
3. 编程能力:代码党可以重点关注
官方资料中,Gemma 4 的核心场景之一就是 coding,包括:
- 代码生成
- 代码补全
- 代码修正
- 开发辅助
也就是说,它并不是“顺便会写点代码”。
而是从设计目标上,就考虑了:
让开发者拿它来做真正的生产力工具。
你完全可以把它用来做:
- 本地代码助手
- Web 开发辅助
- 脚本生成
- Bug 排查
- 项目结构理解
- 自动生成配置文件
尤其如果你重视隐私,不想把代码都扔到云端,Gemma 4 会很有吸引力。
4. Agent 能力:重点中的重点
这次 Gemma 4 一个非常值得注意的升级,是它支持 function calling,并且官方反复提到它适合 agentic workflows。
这是什么意思?
就是说,它不只是适合“你问它答”这种单轮对话。
它更适合接到工具链里去干活,比如:
- 自动检索资料
- 自动调用接口
- 自动整理信息
- 自动执行多步任务
- 自动生成内容或报告
说白了:
Gemma 4 不是只会“陪聊”,它是有点想“上班”的。
5. 多语言能力:对中文用户也更友好
官方给出的信息是,Gemma 4 支持 140+ 语言,其中对 35+ 语言提供较好的开箱能力。
这对中文用户意味着什么?
至少它不是那种:
- 英文状态像博士
- 中文状态像实习生
当然,中文表现是否绝对顶级,还得看具体任务和使用方式。
但至少它在定位上,已经不是“只会英文耍帅”的模型路线了。
为什么这次大家对 Gemma 4 这么上头?
我看了不少公开资料和社区讨论,Gemma 4 这次火起来,核心原因大概有三个。
第一,许可真的很重要
Gemma 4 使用的是 Apache 2.0 许可。
这件事对于开发者、创业团队、企业用户来说,意义非常大。
因为很多模型不是不能用,而是:
试起来很爽,真要上线时就开始心虚。
Gemma 4 在这方面明显更让人踏实。
第二,它真的是在认真做“本地优先”
谷歌官方反复提到 on-device、consumer GPUs、edge devices、phones 这些方向。
这说明 Gemma 4 从一开始就不是只打算活在云端。
它很明显是在传达一个信号:
未来不是所有 AI 都必须上云,本地和边缘端一样重要。
第三,它有种“小模型也能打高端局”的感觉
Gemma 4 的一大叙事就是:
不是只比参数,而是比“同体型下的能力”。
这点非常符合现在本地 AI 的实际需求。
因为大多数人不是在比“谁实验室更豪华”,而是在比:
- 谁更好部署
- 谁更能落地
- 谁更不挑机器
- 谁更像个生产工具
这也是 Gemma 4 这次真正打动人的地方。
怎么选模型?千万别一上来就冲最大号
很多人一装本地模型,就犯同一个错误:
“当然选最强的啊!”
然后下一秒:
- 风扇起飞
- 显存告急
- 推理龟速
- 心态爆炸
所以,选 Gemma 4,最重要的不是“哪个最强”,而是:
哪个最适合你。
如果你只是想尝鲜,或者机器一般
优先试:
- E2B
- E4B
这两个更轻,部署门槛更低,也适合移动端和边缘端场景。
如果你想认真干活,又想兼顾速度
优先试:
- 26B A4B
这是非常典型的“甜点位”。
能力明显强于小模型,但又不像旗舰版那样对资源要求那么激进。
如果你就想冲效果上限
直接看:
- 31B
但前提是,你的机器配置得跟得上。
一个简单粗暴的选型建议
你可以直接按这套逻辑来:
- 轻体验 / 轻部署 / 低资源 → 选 E2B / E4B
- 实用主义 / 本地干活 / 平衡性能 → 先试 26B A4B
- 追求最强输出 / 不太在意资源消耗 → 选 31B
一句话:
不要盲目上最大模型,选对比选大更重要。
怎么安装 Gemma 4?最简单的方式就是 Ollama
如果你第一次本地部署 Gemma 4,最推荐的方式之一就是:
Ollama。
因为它真的省心。
对很多人来说,Ollama 的价值不在于“技术最酷”,而在于:
它能让你少走很多弯路。
第一步:安装 Ollama
先到 Ollama 官网下载安装对应系统版本。
支持 Windows、macOS、Linux。安装完成后,可以先执行:
ollama --version
如果能看到版本号,就说明装好了。
第二步:拉取 Gemma 4 模型
最简单的方式:
ollama pull gemma4
拉完后可以用下面这条命令确认:
ollama list
第三步:按型号运行不同版本
官方文档里给出的标签包括:
gemma4:e2b
gemma4:e4b
gemma4:26b
gemma4:31b
所以你可以根据自己的机器情况,选具体型号来跑。
第四步:直接开始使用
比如:
ollama run gemma4 "用中文解释什么是向量数据库"
如果你要测试图像能力,也可以用带图片路径的方式。官方文档提供了相关示例。
第五步:用本地 API 接自己的应用
Ollama 本地默认会开一个服务接口,你可以直接通过 API 调用模型:
curl http://localhost:11434/api/generate -d '{
"model": "gemma4",
"prompt": "帮我写一个 Python 快速排序"
}'
这样就可以很方便接:
- 自己的脚本
- 本地工具
- 前端页面
- 自动化流程
除了 Ollama,还能怎么用?
如果你不想只走 Ollama,还有不少方式。
1. Hugging Face / Transformers
Gemma 4 已经支持通过 transformers 加载和使用。
适合:
- Python 用户
- 想自定义推理流程的人
- 想自己写调用逻辑的人
2. Google DeepMind 官方 gemma 包
官方 GitHub 提供了 gemma Python 包,也适合研究、实验和更底层的使用。
3. 更多本地生态也在跟进
Hugging Face 的官方介绍里也提到,Gemma 4 正在和更多生态快速打通,比如:
- transformers
- llama.cpp
- MLX
- WebGPU
- Rust 等方向
这说明它不是“模型发了,生态还没准备好”。
而是:
模型一发布,生态已经开始往上扑了。
Gemma 4 适合拿来干什么?
这部分可能是大家最关心的。
别只盯着“参数”和“跑分”,真正重要的是:
它能帮你做什么。
1. 本地代码助手
如果你想要一个能在本地跑、不把代码上传云端的 coding assistant,Gemma 4 很适合重点关注。
尤其是 26B A4B 和 31B。
2. 图像理解与文档处理
如果你经常处理:
- 截图
- 文档
- 表格
- 图表
- 界面草图
Gemma 4 的视觉和 OCR 相关能力会很有用。
3. 本地 Agent / 自动化工具
如果你喜欢折腾自动化工作流,比如:
- 自动抓取信息
- 自动总结
- 自动生成内容
- 自动执行多步任务
Gemma 4 的 function calling 和 agentic workflow 定位会非常有吸引力。
4. 移动端 / 边缘端 AI 应用
E2B / E4B 这两个版本,明显就是冲着端侧和轻量 AI 应用去的。
如果你在做边缘设备、IoT、移动端 AI,值得重点看。
也说几句冷静的话:Gemma 4 不是万能药
虽然这次 Gemma 4 很值得夸,但也不能吹到离谱。
第一,它很强,但不是“从此天下无敌”
现在开放模型生态里,依然有不少强手。
Gemma 4 很能打,但并不意味着别的模型都可以回家睡觉。
第二,榜单成绩不等于你本地体验自动满分
你实际体验会受到很多因素影响:
- 量化方案
- 推理框架
- 上下文长度
- 图片输入大小
- 显卡和内存
- 是否启用 thinking mode
所以别期待“装完立刻封神”。
第三,小模型很能干,但别神化
E2B 和 E4B 再优秀,也还是轻量模型。
如果你要做特别复杂的长链路推理、重度工程代码理解、大规模多步骤任务,26B A4B 和 31B 仍然更稳。
最后给一个最实用的建议
如果你现在想开始用 Gemma 4,不用想太复杂。
直接按这个步骤来:
路线一:你只是想先试试
- 装 Ollama
- 拉
gemma4:e2b或gemma4:e4b - 先跑文本、图片理解
- 感受一下整体风格和能力
路线二:你想认真做点事
- 直接试
gemma4:26b - 拿来做代码辅助、知识整理、自动化脚本、Agent 流程
路线三:你机器够强,想冲上限
- 上
gemma4:31b - 追求更好的推理、代码和多模态表现
一句话:
别先问“最强的是谁”,先问“哪一个最适合我”。
总结:Gemma 4,为什么值得你现在就关注?
因为它很少见地把几件事情同时做好了:
- 模型能力在线
- 多模态能力完整
- Agent 能力明确
- 本地部署友好
- 许可足够宽松
- 开发者生态跟得上
它最大的意义,不只是“谷歌又发了一个模型”。
而是:
谷歌终于认真拿出了一套,既能打、又能用、还能放心拿去落地的开放模型家族。
所以如果你现在正想找一个:
- 能本地运行
- 性能够强
- 支持多模态
- 还能接入自动化工作流
的大模型,
那么 Gemma 4,确实已经是目前最值得尝试的一批选择之一。
参考与资源链接
官方资料
- Google 官方发布博客:Gemma 4
https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Google AI Developers:Gemma 文档总览
https://ai.google.dev/gemma/docs/core - Gemma 4 官方 Model Card
https://ai.google.dev/gemma/docs/core/model_card_4 - Gemma Apache 2.0 许可说明
https://ai.google.dev/gemma/apache_2
部署与使用
- Gemma + Ollama 官方文档
https://ai.google.dev/gemma/docs/integrations/ollama - Google DeepMind Gemma GitHub
https://github.com/google-deepmind/gemma
补充参考
- Google Developers Blog:Gemma 4 与端侧 Agent
https://developers.googleblog.com/bring-state-of-the-art-agentic-skills-to-the-edge-with-gemma-4/ - Hugging Face:Gemma 4 介绍
https://huggingface.co/blog/gemma4 - Arena AI 文本榜单
https://arena.ai/leaderboard/text


文章评论