大家好,我是蓝戒。本篇我们来聊聊:"TencentDB Agent Memory"。
你是不是也遇到过这种让人抓狂的场景:给AI Agent(自治智能体)安排了一个复杂的长任务,写代码、查资料、调工具忙活了半天,结果它越聊越糊涂,最后干脆“断片”了?或者,为了让它记住之前的对话,你把成千上万行的网页源码和报错日志一股脑塞进上下文窗口,结果月底一对账,Token费用高得让人想连夜跑路,而AI却在庞杂的信息里“迷失自我”,开始满嘴胡言(幻觉)。
这就是行业里典型的“上下文认知悖论”:塞满历史会Token暴涨、注意力分散;粗暴截断或压缩又会让AI丢失关键线索,变成“金鱼脑”。
为了打破这个认知瓶颈,腾讯云数据库团队出手了!他们推出并开源了一款名为 TencentDB Agent Memory(代号“龙虾”)的记忆服务引擎。别误会,它可不是那种只会搞“向量相似度盲目搜索”的普通数据库,而是一个专门给AI助理(如 OpenClaw、Hermes)装上高智商、能省钱的“分层白盒记忆大脑”。
今天,我们就用大白话来盘一盘,这个引擎到底是怎么把AI的健忘症治好的。
一、 别再暴利堆砌了!记忆也需要“渐进式披露”
市面上很多传统的记忆方案,做法非常粗暴:把聊过的话切成碎片,变成一堆密密麻麻的数字(向量)存起来,AI要用的时候就去捞。这种扁平化的存储方式,根本没有宏观逻辑,捞出来的碎片信息经常前言不搭后语。
TencentDB Agent Memory 提出了一个核心哲学:拒绝扁平,拥抱渐进式披露。简单来说,就是“低层保留证据,高层保留结构”。
它采用了异构存储双轨制,把AI的记忆分成了两条线:
- 非结构化底层证据流: 原始的聊天记录、工具调用日志、报错堆栈。这些信息很重,但很重要。系统把它们持久化在本地关系数据库(如 SQLite + sqlite-vec 向量扩展)里,作为“冷数据”备查,确保证据绝对不丢失。
- 结构化高层语义图: 用户的习惯画像、高频场景、技能流程图。这些高密度、人类和AI都能轻松读懂的信息,被精简成 Markdown 文件和 Mermaid 语法,统一保存在本地目录中。
最绝的是,它设计了一条完美可逆的溯源链条。AI日常推理时,只需要加载极其轻量的高层结构图(省Token);一旦执行任务遇到异常,它可以像顺藤摸瓜一样,通过索引一键向下钻取,瞬间恢复最底层的原始对话或报错快照。这种无损的证据链,既保证了AI不迷失,又榨干了Token的性价比。
二、 从“原始记录”到“稳定认知”:L0 到 L3 的语义金字塔
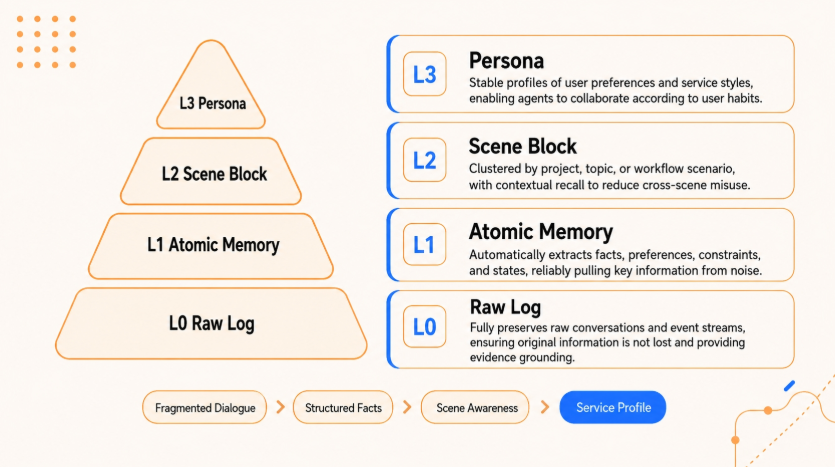
为了搞定长期的个性化记忆,TencentDB Agent Memory 在纵向上搭了一个“语义金字塔”,信息由下至上提炼,越往上越精简:
语义金字塔层级拆解
| 记忆层级 | 物理载体与格式 | 数据内容 | 检索与激活策略 | 认知功能对应 |
| L3 Persona (画像层) | 本地 Markdown 文件 | 用户的宏观偏好、表达风格、长期目标 | 每轮对话初始化时,作为核心上下文首批载入 | 语义记忆(稳定的自我与客体认知) |
| L2 Scenario (场景层) | 独立场景块 (Markdown) | 特定业务场景、频繁协作的上下文边界 | 检测到当前话题切入特定场景时,整块激活 | 情境记忆(特定时空的事件聚类) |
| L1 Atom (事实层) | SQLite / JSON 格式 | 具名实体关系、单一决策点、静态事实 | 依靠混合检索,在细节考证时精准召回 | 联想记忆(离散的事实网格) |
| L0 Conversation (对话层) | 原始对话记录数据库 | 原始文本、时间戳、发送者元数据 | 默认不注入上下文,仅作为审计回溯的冷数据 | 感官登记(未经处理的信息原始流) |
日常聊天时,AI优先调用最顶层的 L3 画像来把握大方向。只有当它需要考证具体某个项目细节时,检索指针才会向下钻取。这种金字塔设计,不仅节约了宝贵的上下文空间,还显著降低了AI瞎编乱造的概率。
三、 两个大招:上下文卸载 与 Mermaid 无限画布
在写代码或深度网络检索时,工具返回的代码段或网页 HTML 动辄几万 Token。针对这个问题,引擎放了两个大招:
1. 上下文卸载机制 (Context Offloading)
当AI调用终端或发出网络请求时,那些臃肿的原始输出不再直接写入大模型的上下文历史,而是被即时重定向、脱水并卸载到外部本地文件系统里。在AI的窗口里,只留下一行精炼的 Summary 标签和唯一引用指针。实验表明,单靠这一手,就能为上下文窗口释放约 15% 的空间!
2. Mermaid 无限画布 (Mermaid Infinite Canvas)
光卸载还不够,AI如果只看到一行行孤立的标签,还是会懵。于是,系统把任务的执行历史,画成了一幅基于 Mermaid 语法 的动态流程图画布。
为什么选 Mermaid?
- 天生就会: 大模型在预训练时读过海量的图表,对 Mermaid 具有天然的强解析能力。
- 低认知负载: 它是文本化的语法,没有 JSON 那种冗余的括号,极省 Token。
- 自由度高: AI可以根据网络超时、编译失败等现实情况,在画布上自由分叉、重试或修剪任务链。
当AI在上下文里看到的是一幅高密度的 Mermaid 任务图谱时,它能瞬间明白“我是谁、我在哪、我下一步该干嘛”,避免了无意义的工具重复调用。
四、 业界主流方案横向对比:它凭什么胜出?
在 AI Agent 记忆引擎的赛道里,我们挑了两个明星方案——Mem0 和 Letta(原 MemGPT),跟 TencentDB Agent Memory 做个同台竞技:
核心方案多维度横向对比
| 评估维度 | Mem0 | Letta (原 MemGPT) | TencentDB Agent Memory |
| 设计哲学 | 被动事实提取层(离散事实持久化) | Agent 操作系统运行时(物理内存读写) | 分层渐进披露认知引擎(短期符号图+长期金字塔) |
| 短期记忆处理 | 无特殊设计,依赖开发者自行截断 | 三级物理分页,靠 Agent 主动函数换入换出 | 上下文卸载 + Mermaid 无限任务画布自动折叠 |
| 白盒可观测度 | 较低。调用后黑盒提取,难以定位源头 | 较低。依赖 Agent 自行更新,容易断裂 | 极高。100%可逆下钻链路,支持纯文本离线审查 |
| 推理成本开销 | 极低。事实提取在旁路异步完成 | 极高。推理循环中频繁调工具,极耗 Token | 极佳。短期任务最高节省 61.38% Token,分层避免污染 |
| 系统侵入度 | 极低。调用 add() 和 search() 即可 | 极高。必须完全运行在其内部,迁移困难 | 低/中等。提供开箱即用插件,也支持独立网关部署 |
五、 性能飙升:实测数据里的硬实力
在连续执行 50 个复杂任务的极限压力测试中,接入 TencentDB Agent Memory 插件前后的对比数据非常惊艳:
- WideSearch(大批量网页检索场景):
- 原生框架成功率:33% $\rightarrow$ 接入后成功率:50%(提升 51.52%)
- 原生 Token 消耗:221.31 M $\rightarrow$ 接入后 Token 消耗:85.64 M(Token 节约率高达 61.38%!)
- SWE-bench(软件工程高强度测试场景):
- 原生框架成功率:58.4% $\rightarrow$ 接入后成功率:64.2%(绝对提升近 10%)
- 原生 Token 消耗:3474.1 M $\rightarrow$ 接入后 Token 消耗:2375.4 M(节约 33.09%)
在涉及大量冗余 HTML 的场景中,大模型的注意力很容易被各种标签污染。系统把源码彻底卸载后,实际输入大模型的 Token 量急剧收缩。而在代码修复测试中,AI得以完全专注于 Mermaid 画布上展现的 Bug 拓扑,任务完成率直接起飞。
六、 开发者落地指南:两步搞定本地集成
TencentDB Agent Memory 已经提供了完善的工程化调用接口。如果你使用的是 OpenClaw,只需简单两步即可启用:
1. 插件安装与零配置启用
在控制台执行命令行安装并重启服务:
Bash
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
openclaw gateway restart
接着,在配置文件 ~/.openclaw/openclaw.json 中声明启用:
JSON
{
"memory-tencentdb": {
"enabled": true
}
}
2. 开启短期上下文卸载与 Mermaid 压缩
编辑配置文件,配置 offload 节点,并将上下文处理路由至该插件:
JSON
{
"plugins": {
"slots": {
"contextEngine": "memory-tencentdb"
}
},
"memory-tencentdb": {
"enabled": true,
"config": {
"offload": {
"enabled": true
}
}
}
}
最后,运行核心 Hook 补丁脚本。该脚本会在工具调用完成后挂载拦截器,确保详细日志能被无缝剥离并重定向:
Bash
bash scripts/openclaw-after-tool-call-messages.patch.sh
(提示:每次 OpenClaw 升级后,重新执行一次该补丁脚本即可。)
此外,系统还支持通过 Docker 一键部署独立的 Hermes 认知 Gateway,适配任何 OpenAI 兼容标准的模型接口(如配置大模型基础地址指向腾讯云大模型知识引擎 LKE,指定 deepseek-v3.2 等强推理模型),并内置了常量时间抗侧信道攻击算法等生产级安全加固策略。
结语
TencentDB Agent Memory 的开源,宣告了 Agent 记忆管理正式告别了盲目平铺向量的“大熔炉”时代,迈入了可结构化、可逆向溯源的“白盒认知”新纪元。它不仅帮开发者狠狠地裁剪了推理成本,更让 AI Agent 跨越了“只懂执行单步工具”的初始阶段,开始朝着“能自主沉淀经验、可白盒审计、能自发学习成长”的数字员工加速演进!


文章评论